RNN
普通神经网络不能考虑之前一个单词对下一个单词的作用,即上下文,因此引入RNN。
RNN在中间层加入了memory,在每次传播后,将中间层输出存储到memory,在下一次传播时,将结果取出与原输入一起作为输入,之后再传出到下一层。
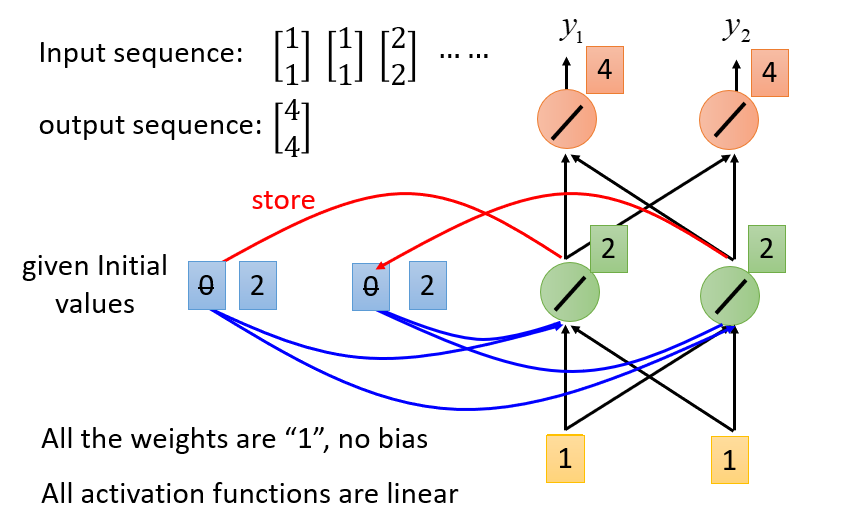
以下图为例,为了方便演示,将激活函数全部变为线性,并且权重设为1,假设一开始,输入矩阵$[1,1]^T$,那么会输出$[4,4]^T$,同时两个记忆体由0变为2(因为隐藏层的输出是2)
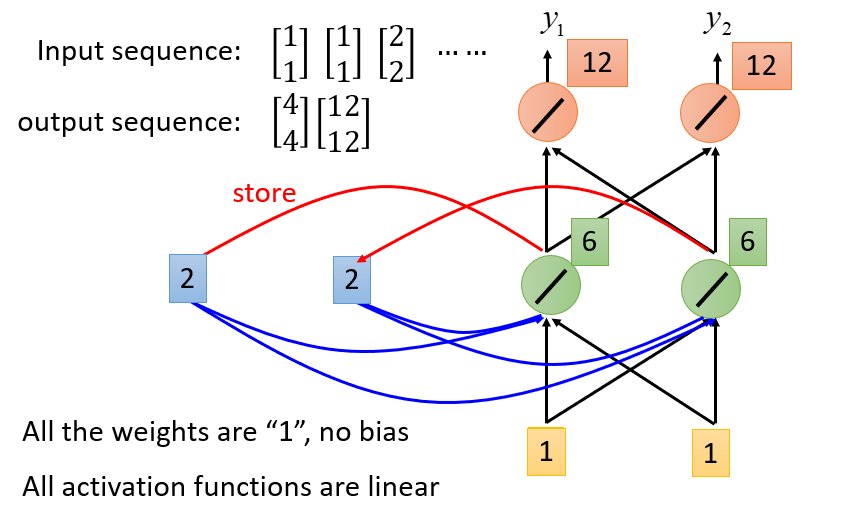
那么接下来,输入矩阵$[1,1]^T$,这次虽然输入是一样的,但是由于memory不同,而memory也是输入的一部分,因此隐藏层输出为$[6,6]^T$,最终出$[12,12]^T$
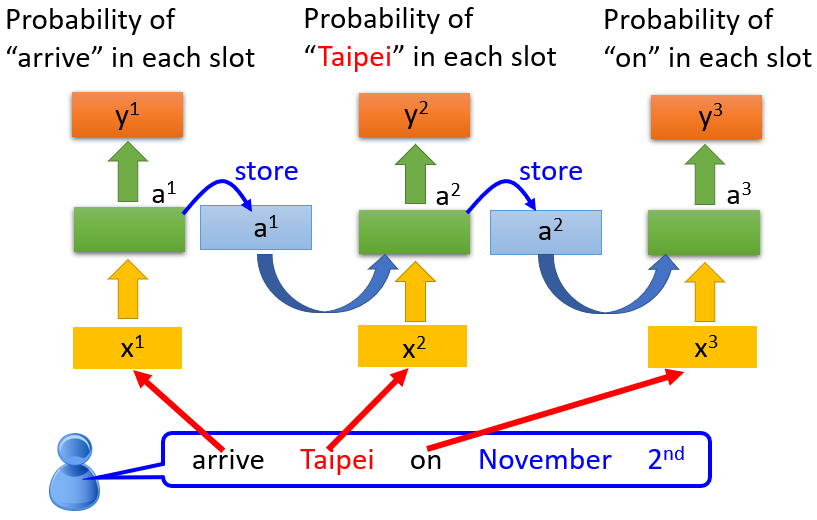
因此输入个向量序列后,大致会执行类似下图流程
可以将其变形为深度学习模型,即存在多个隐藏层
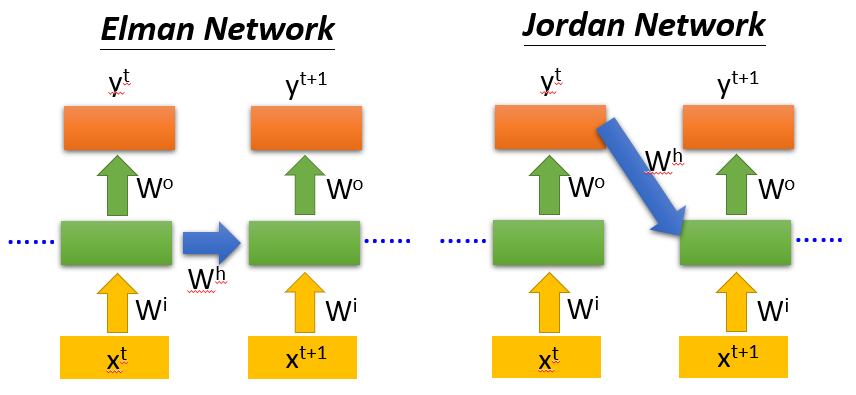
同时,其有如下变形
Elman Network: memory存中间值
Jordan Network: memory存output值
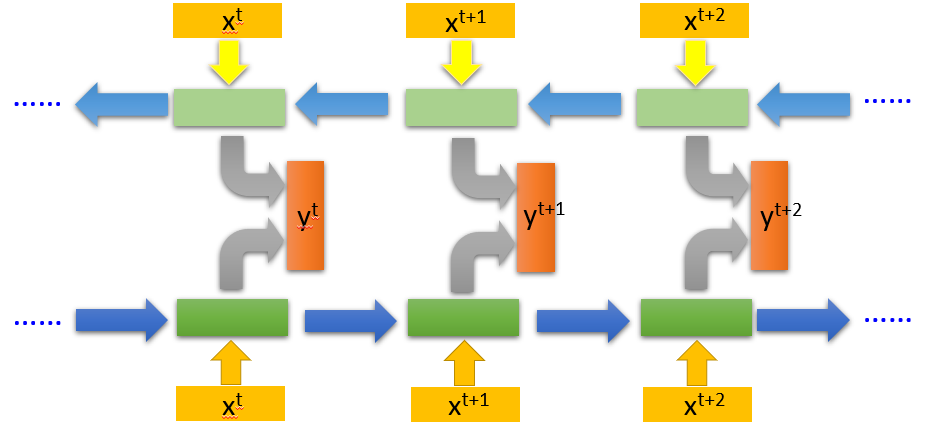
Bidirectional RNN
同时train正向和反向的神经网络,结合两个网络的output结合得到最终output:
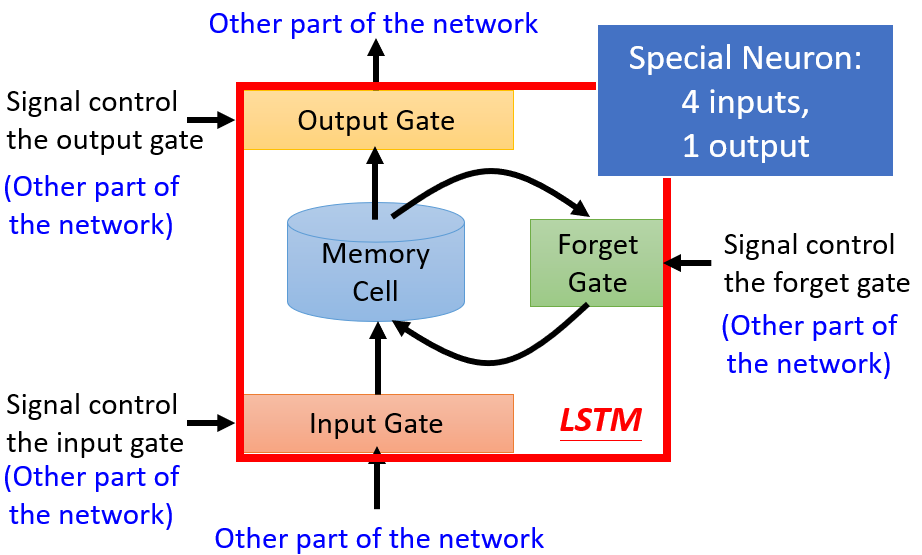
Long Short-term Memory(LSTM)
如下图所示,对于记忆体增加三个闸门:
Input Gate:控制其他神经元能否写入记忆体
Output Gate:控制其他神经元能否读取记忆体
Forget Gate:控制记忆体是否该格式化数据
因此该神经网络有四个输入,一个输出,是否开放Gate由网络学习得到
参考资料
Machine Learning (Hung-yi Lee, NTU) , https://www.youtube.com/watch?v=CXgbekl66jc&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49 (图片来源,李老师讲的课真的很好,大家可以听听看)