本文首次发表在慕测头条公众号,这里只作归档用
背景意义
随着人们对软件安全的不断重视,静态安全扫描系统被部署于开发流程。相对于其他传统分析方法,污点分析技术由于具有较高的可解释性和准确性,目前作为挖掘 Web 漏洞的常用技术,广泛应用于开源和商用扫描器中。
然而,污点分析方法存在种种不足。首先,污点分析无法处理容器类型,静态污点分析只能将容器变量(如Map、List变量)的传播规则设为传播/不传播污点,造成过污染/欠污染;其次,污点分析无法处理控制流,污点分析并不能识别用于检查数据是否合法的分支语句,导致误报;最后,污点分析无法处理特殊的传播条件,如SSRF漏洞要求攻击者能操纵域名,若污点拼接在URL参数部分,则代码不存在漏洞,而污点分析仍会报告漏洞。为解决这些问题,目前安全工程师只有手动设计精巧的规则,可即使这样仍会产生大量误报甚至漏报。
为解决传统分析方法高误报、需要花大量人力定义规则等问题,随着机器学习领域的不断发展,学术界一直在探索机器学习在静态安全扫描上的应用。李珍等学者使用后向程序切片结合BLSTM神经网络进行漏洞挖掘[1],然而他们的工具只能用于C/C++编写的软件,Koc 等学者提出使用类似技术对Java代码漏洞进行过滤[2,3],通过预测误报提高扫描结果准确性,实验证明该工具具有很好的效果,然而由于传统程序切片过于耗时,其工作只能对污点传播的最后一段函数体进行切片,污点传播是否能够传播并不等价于污点是否能够在汇聚点传播,因此他们的工作无法用于实际场景。
可见,一款实际可用的基于机器学习的Java静态漏洞扫描系统能有效减轻工程师工作量,在快速开发软件的同时保证软件安全性。
系统介绍
本系统结合最新学术界成果,面向 Web 开发常用的 Java 语言,利用污点分析、程序切片和 BLSTM 为开发或安全工程师提供更准确的代码扫描服务。其工作流程如下图所示,工程师在系统中新建扫描项目,在项目中提交源代码和Jar包;污点分析模块对 Jar 包进行污点分析,得到污点传播报告,污点报告中包含有漏洞实例和对应的污点传播树;程序切片模块将对传播树分解为污染流,并对每一污染流进行切片;数据预处理模块对切片进行泛化和向量化处理,得到切片的特征向量;预测模块通过BLSTM模型对切片进行预测,从而推导漏洞是否为误报;至此,系统将更精准的漏洞报告返回至用户。
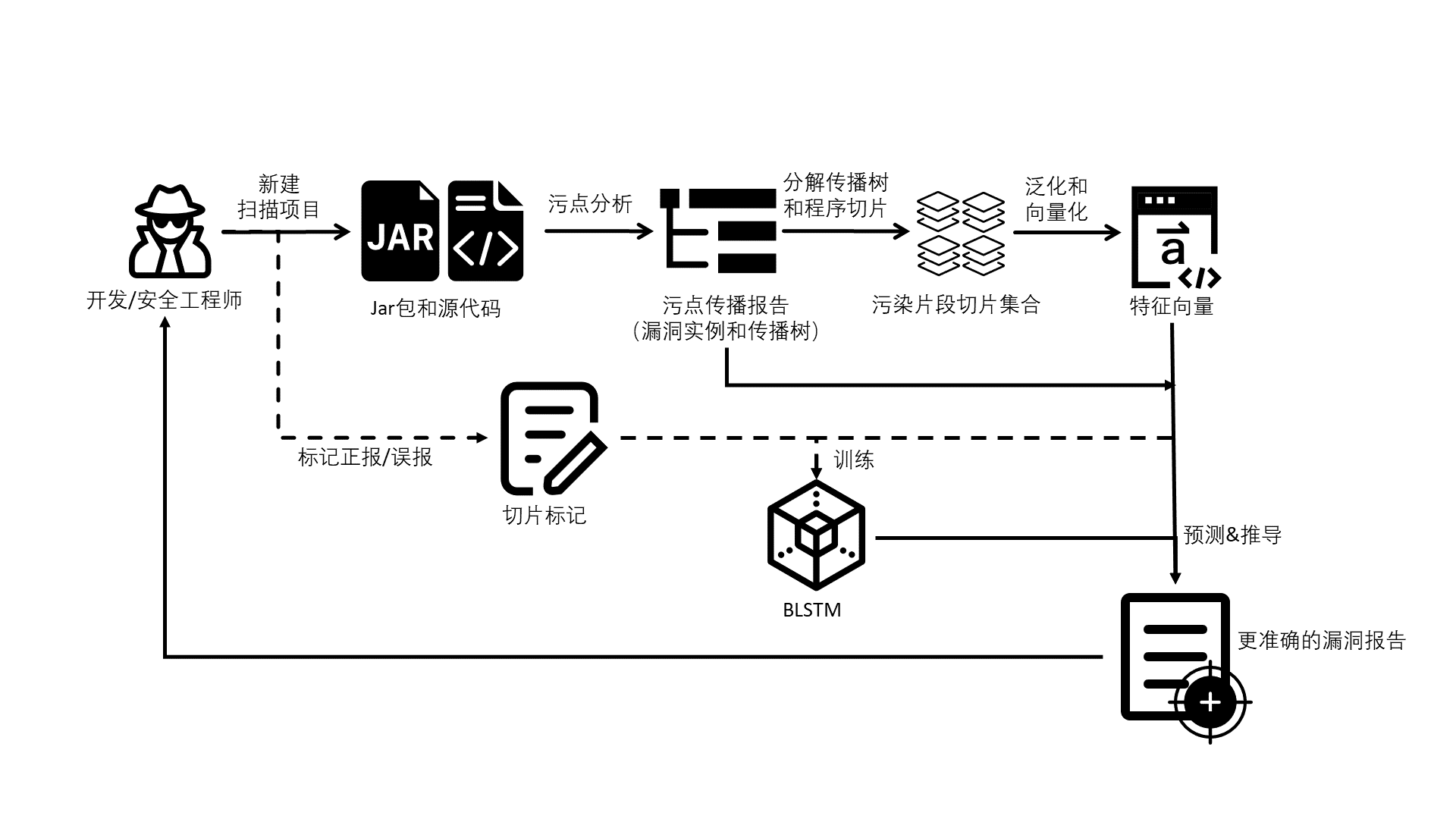
在污点传播过程中,系统对FindSecBugs的污点分析过程进行改造,使其在报告中返回污点传播树,污点传播树表示污点的唯一传播路径,为程序切片提供依据。例如,对于代码 1 来说,在污点传播报告中返回如图 1所示的传播树,可见传播树的树根为污点入口函数上下文,叶子节点为函数调用或返回语句,且叶子节点存在顺序,且终止于汇聚点,注意尽管代码中存在if分支,但有的分支返回语句与污点无关,因此最终只有一个污点传播树。
在程序切片过程中,系统对污点分析报告中的漏洞实例进行切片,为解决切片规模巨大造成扫描时间过长甚至扫描失败的问题,在切片前,系统通过限制调用图节点个数保证切片快速完成;同时,为保证切片覆盖污点传播全阶段,系统对一个漏洞进行分段切片,对于一个漏洞的每一传播树,将其拆解为污点传播片段,由“函数摘要→兴趣点行号”二元组表示,再对每个片段进行切片,例如图 1 的污点传播树,将会产生doGet()→line:5、filter()→line:13和sink()→line:17 3个切片。

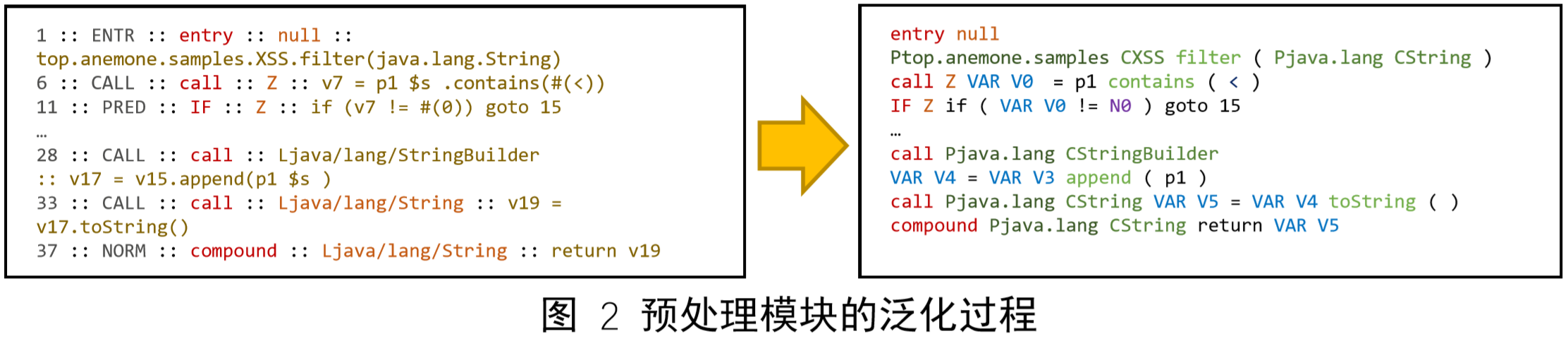
在预处理过程中,系统对每一切片进行泛化和向量化处理,图 4 将说明泛化过程,图中左侧为原始切片输出,其每行代表一个SDG节点,SDG节点由“序号::节点类型::指令类型::返回值::具体内容”构成,预处理过程保留节点类型、指令类型和具体内容,并对切片中数字常量、字符串常量、变量、函数调用和类名方法名进行抽象,经过泛化后切片如右侧所示。向量化过程将泛化后的单词序列转化为数字向量,用于传入神经网络。
在误报预测过程中,系统首先通过BLSTM神经网络预测每一污点传播片段是否可以传播污点,再通过污点传播规则推导漏洞是否为误报,即:若传播树中国任意一个阶段不能传播污点,那么该传播树无法利用;若漏洞中所有传播树无法利用,那么标记该漏洞为误报。例如代码 1 中,首先BLSTM模型很可能预测到filter()→line:13 切片无法传播污点,因此对应的污点传播树不可利用,又因为漏洞只有一个传播树,因此系统判断漏洞为误报。
下图展示了系统中代码 1的预测结果,该实例的节点已经变灰,且预测显示为“[P:FP]”(误报),左下方被预测为清洁函数已由清洁标记标注,这些标记向用户解释系统为何将其预测为误报,这说明本系统是真实有效的。
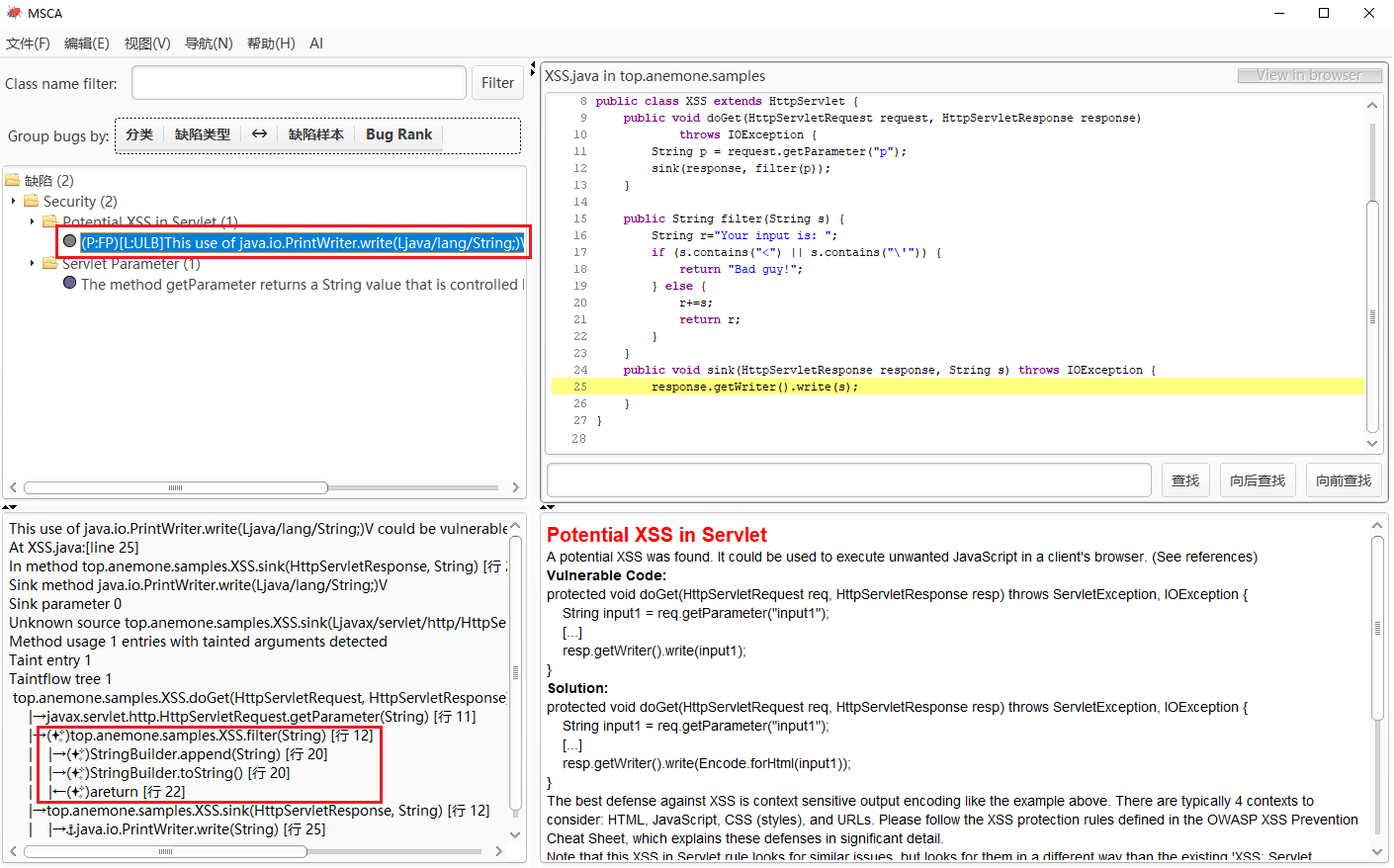
对于污点传播报告,用户可以标记为正报或误报。对于正报,用户需至少指定一个可利用的污点传播树;对于误报,用户需指定若干条污点无法传播的片段,直到系统根据污点传播规则将其推导为误报。
项目效益
为证明系统准确性,本文将本系统与目前流行的扫描工具 FindSecBugs 对比,以OWASP Benchmark v1.1中污点传播类漏洞作为数据集,比较两者的准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1。
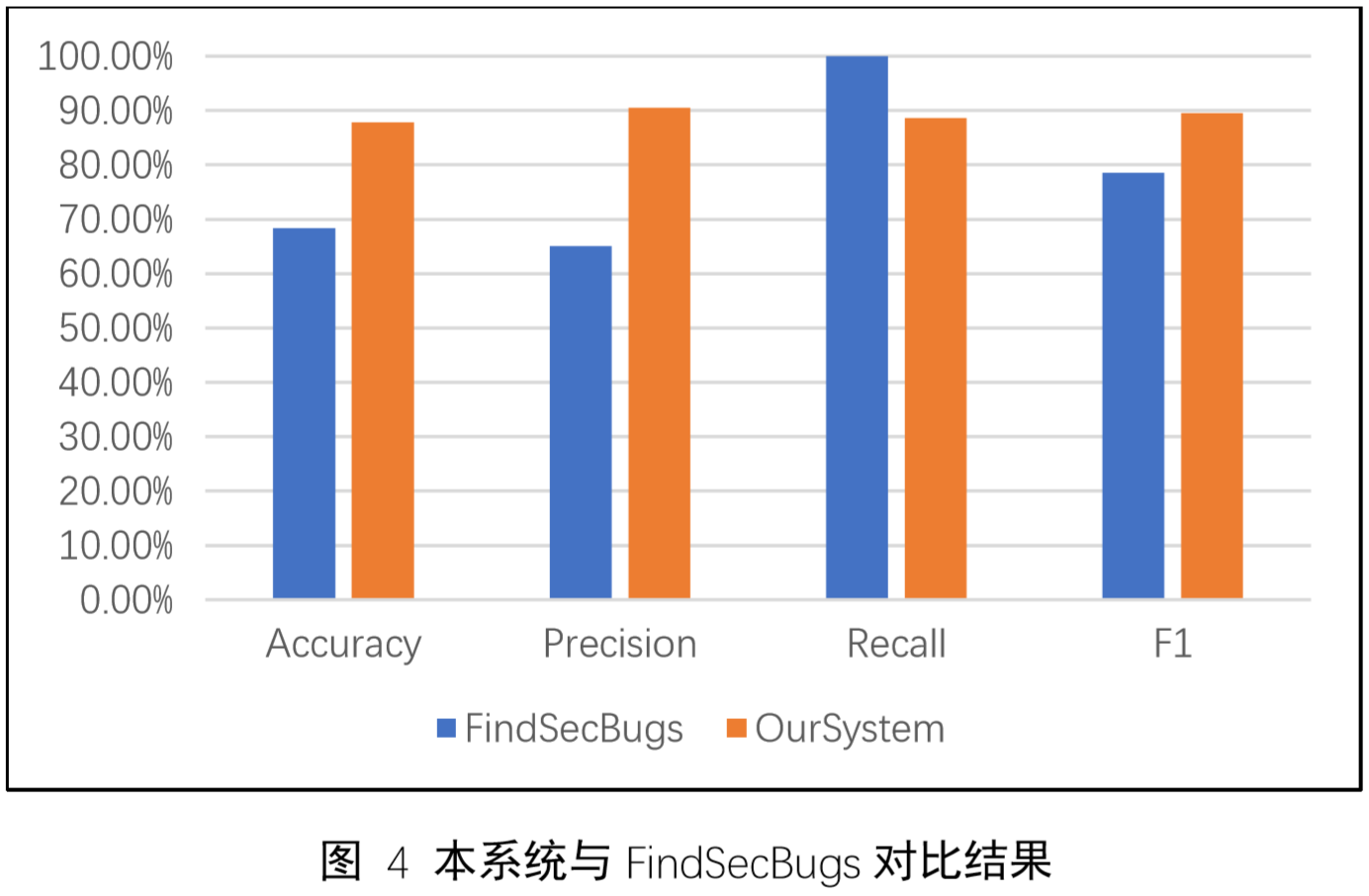
结果如图 4 所示。可以看出,为了不发生漏报,Find Security Bugs 产生非常高的误报率(误报率为1-65.09%=34.91%)从而导致准确率和 F1 值水平也较低,不准确的漏洞报告不仅会给安全工程师造成巨大压力,更可能造成项目开发进度被阻塞,而本系统结合污点分析和机器学习的优势,仅牺牲 11.35% 的召回率,将精确率提高到 90% 以上,即平均系统中报告的 10 个漏洞中,只有一例可能为误报。在准确率和 F1 指标上也远高于 Find Security Bugs,这说明牺牲召回率具有较高的收益比。
综上,相较于传统污点分析类扫描器,本系统能更准确地发现漏洞,并且以较小的代价提升准确性。
总结
本文介绍了一款基于机器学习的Java静态漏洞扫描系统,基于学术界前沿工作,相对于传统扫描工具本系统能提供更准确的扫描结果,同时系统解决了学术工具只能应对小规模程序的问题,使其可用于实际生产环境。在未来工作中,我们将会覆盖更多漏洞类型、扩充学习数据并对特定漏洞独立训练模型,使扫描报告更加准确。
相关链接
Li Z, Zou D, Xu S, et al. Vuldeepecker: A deep learning-based system for vulnerability detection[J]. // Proceedings of the 2018 Network and Distributed System Security Symposium
Koc U, Saadatpanah P, Foster J S, et al. Learning a classifier for false positive error reports emitted by static code analysis tools[C]//Proceedings of the 1st ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. 2017: 35-42.
Koc U, Wei S, Foster J S, et al. An Empirical Assessment of Machine Learning Approaches for Triaging Reports of a Java Static Analysis Tool[C]//Proceedings of the 12th IEEE Conference on Software Testing, Validation and Verification (ICST). IEEE, 2019: 288-299.