基本介绍
半监督(Semi-supervised Learning)即输入小部分已标记数据和大部分未标记数据进行学习,以提升准确率的一类机器学习方法。
有两种用法:
- Transductive learning:无标记数据就是测试集本身
- Inductive learning:无标记数据不是测试集
之所以有效果的原因:未标记的数据的特征是有价值的,例如下图,未标记的样本分布决定SVM的超平面怎么划:

但是这也不绝对,因为如果左下的数据点时狗的话那么平面就不是这样了,因此半监督不一定效果好,其关键在于假设是否符合实际。
Semi-supervised Generative Model(生成式方法)
先给出初始值,接着计算无标记数据的$p\theta(C_1|x^u)$,再更新模型的$P(C_1)$和$\mu$,反复迭代直到算法收敛

Self-training
- 用标记数据生成模型
- 用模型预测未标记数据
- 将部分预测的标记数据从未标记数据中移到已标记数据中,再回到第一步,这里移动的策略需要自己决定

Generative Model & Self-training
Generative Model对未标记数据属于哪一类不是确定的,而是一个可能性,而Self-training对与未标记数据会给出属于哪一类,非黑即白。
对于神经网络来说,Generative Model不适用
对于直推学习来说,Self-trainging不适用(因为未标记的数据本身就是需要预测的,第一次已经能给出结果)
Entropy-based Regularization
Self-training的优化版,使其适用于神经网络,其思想是认为,如果$y^u$的分布较为集中,那么分类效果比较好,而若$y^u$分布不集中,则神经网络效果较差,因此再损失函数总增加E的度量,E为Entropy,表示了分布是否集中

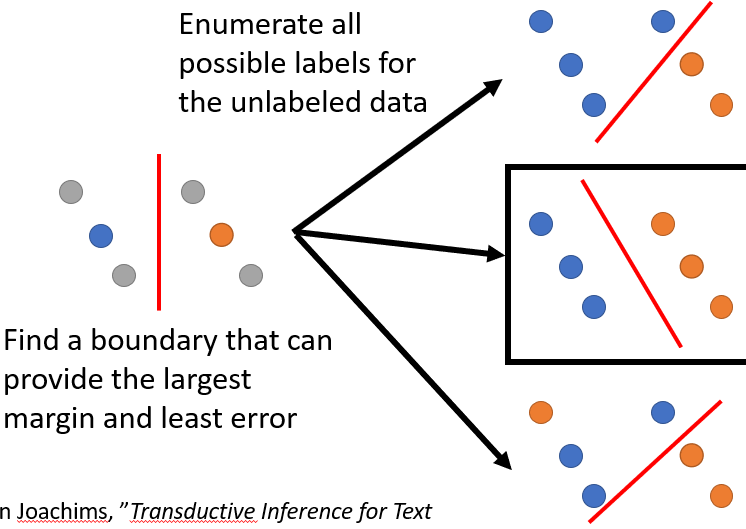
Semi-supervised SVM
枚举未标记的所有可能性,最大化margin和least error
Smoothness Assumption
假设:如果$x_1$和$x_2$相似,那么$y_1$可能等于$y_2$,更准确的说,$x_1$和$x_2$在同一高密度的区域的区域上,那么它们可能一致(感觉很像基于密度的聚类算法)
又由于未标记样本的特征可以填充密度,理论上是有效的。
因此具体做法:先聚类,然后再Label
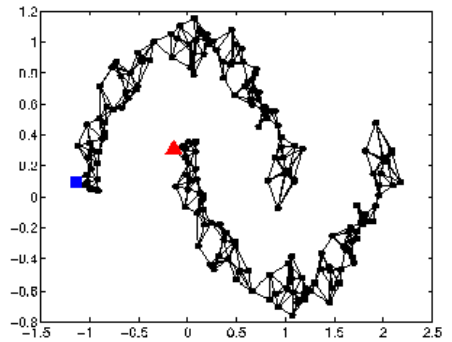
Graph-based Approach
将$x$视为点,在点之间连边,构成图,如果两点之间可达,那么认为两条数据是相似的。如下如,方块和三角虽然距离很近,但是由于它们不可达,因此它们不相似
有些时候,这些边是现成就有的,比如说论文之间的互相引用,网页间的超链接。
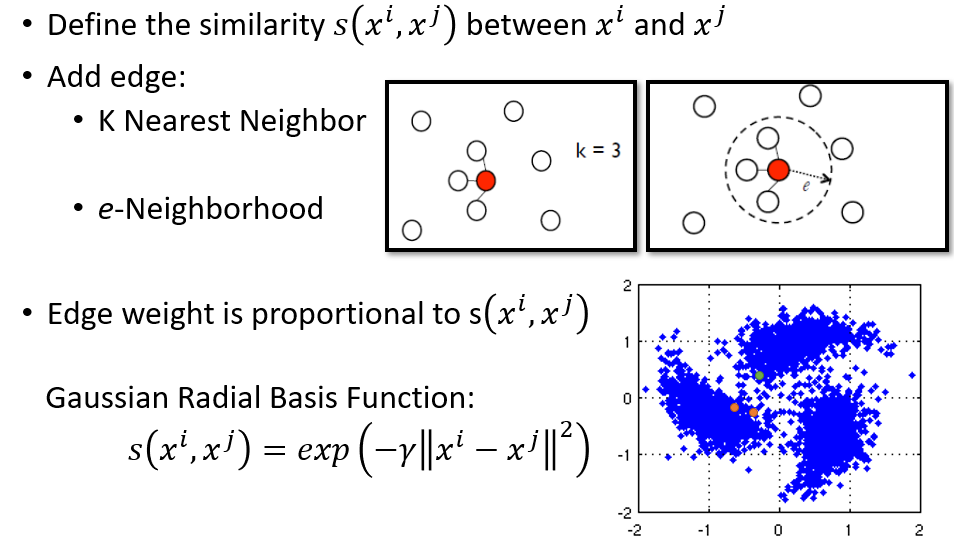
有些情况下是没有的,只能通过一些经验来构造边,比如使用k近邻,e-近邻(推荐),如下图所示,距离推荐使用Gaussian Radial Basis,只有靠近的点才会符合要求
该方法的优势在于赋予了标记数据“传染性”,其可以延边传播到所有类成员。劣势在于未标记数据要足够多,否则无法传递。
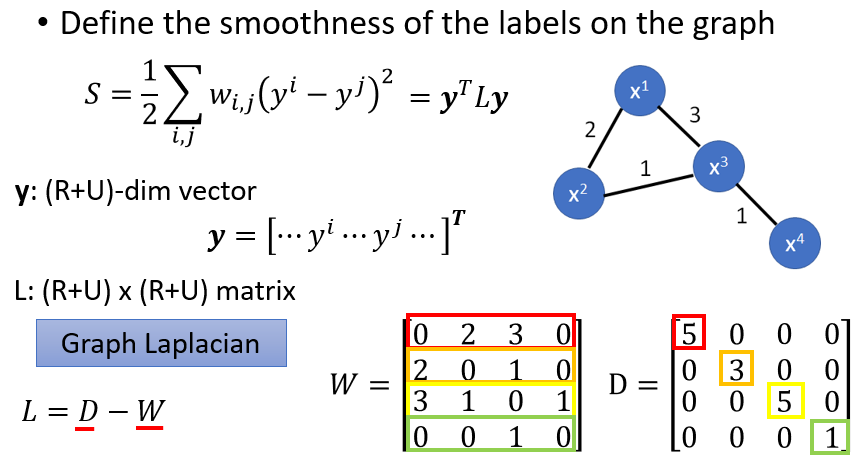
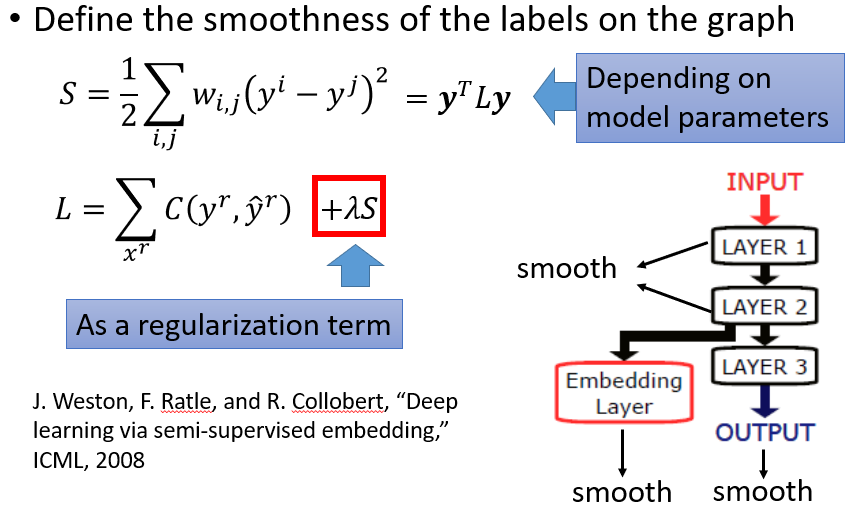
定量分析smoothness:

另外$S$可以通过矩阵运算得到,即计算L, W为图的邻接矩阵,D的对角线上的值为每行的和
在神经网络传播时,将S乘上权重$\lambda$加到损失函数上:
Disagreement-based method(基于分歧的方法)
首先提出多视图的概念,即一个数据对象在多个方面存在多个数据集,比如电影,就存在图像画面的数据集和声音的数据集(两个视图),因此对于多个方面(视图)建立多个模型。
多个模型间可以展开协同训练,即先在每个视图上,使用已标记的数据训练出分类器,让每一个分类器标记未标记的数据,选择最有把握的未标记样本赋予伪标记放入训练集,再将新的训练集给另一视图上的分类器训练,直到分类器结果不再变化。
该方法经过改造,可以用于单视图,仅需不同分类器就可提升效果。
参考资料
Machine Learning (Hung-yi Lee, NTU) , https://www.youtube.com/watch?v=CXgbekl66jc&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49 (图片来源,李老师讲的课真的很好,大家可以听听看)
周志华. 机器学习[M]. 清华大学出版社, 2016.